イネの「ゲノム選抜AI」を構築、品種改良の加速化に期待/農研機構
農研機構は1月8日、これまで蓄積してきたイネのデータを整備、その一部を用いて「ゲノム選抜AI」を構築したと発表した。これによって、ゲノム情報(=個体の形質を決定づける遺伝子の総体)から米の収量や玄米品質等の重要な形質を予測することが可能となり、「イネの品種改良の加速化・効率化が期待できる」としている。
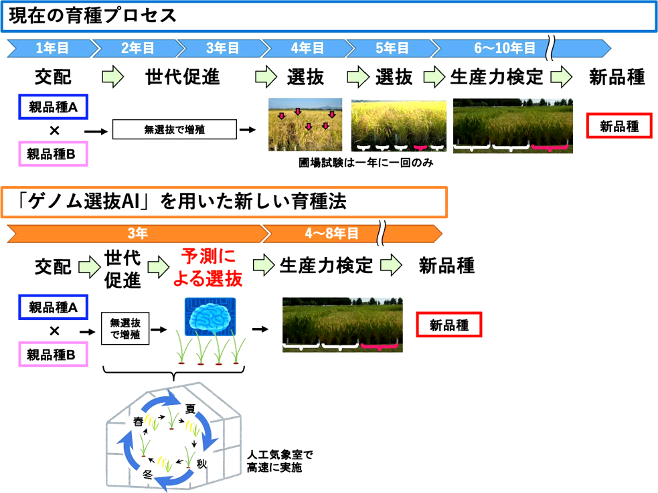
これまでイネの品種改良は、交配と選抜を繰り返したのち、実際の圃場で栽培試験を重ねるというプロセスで行われてきた。そのため、新品種に至るまでは「10年程度の時間と労力と試験のための広い水田が必要」とされてきた。
農研機構は近年、ゲノム情報を用いた品種改良に取り組んできたが、「データが膨大かつ複雑で限界があった」としている。そこで、これまで蓄積してきたイネの形質データを整理・デジタル化し、新たに解析・取得したゲノムデータを追加してデータベース化。ゲノムデータだけでイネの収量や品質を高い精度で予測できる「ゲノム選抜AI」の構築に至った。
ゲノムデータは苗の段階で抽出することが可能なため、試験栽培を収穫まで行う必要がなく「イネ育種にかかる時間を2年程度短縮することが期待できる」としている。収量や品質の実測値と「ゲノム選抜AI」によって導かれた予測値を比較すると「良い精度で予測できた」という。
農研機構は今後「日本型品種の良食味とインド型品種の多収性を併せ持つ画期的品種の育成の加速化が期待できる」とした。
〈米麦日報2021年1月12日付〉








